

正如我们所知,生成式人工智能已经不可逆转地改变了搜索。
谷歌搜索生成体验(SGE)的快速改进和桑达尔·皮查伊(Sundar Pichai)最近关于其未来的声明表明它会继续存在。
信息的考虑和呈现方式的巨大变化威胁着搜索渠道(付费和自然)的运作方式以及所有通过其内容获利的企业。这是对该威胁性质的讨论。
在撰写《SEO 科学》时,我继续深入研究搜索背后的技术。生成式人工智能和现代信息检索之间的重叠是一个圆圈,而不是维恩图。
自然语言处理 (NLP) 的进步始于改进搜索,为我们带来了基于 Transformer 的大型语言模型 ( LLM )。法学硕士使我们能够根据搜索结果中的数据推断内容以响应查询。
让我们来谈谈这一切是如何运作的,以及 SEO 技能组的演变来解释它。
什么是检索增强生成?
检索增强生成(RAG)是一种范例,其中基于查询或提示收集相关文档或数据点,并附加为几次提示以微调语言模型的响应。
通过这种机制,语言模型可以“基于”事实或从现有内容中学习,以产生更相关的输出,并且产生幻觉的可能性更低。

虽然市场认为微软通过新的 Bing 引入了这一创新,但 Facebook 人工智能研究团队于 2020 年 5 月在NeurIPS 会议上发表的论文《知识密集型 NLP 任务的检索增强生成》中首次发布了这一概念。然而,Neeva 是第一个在主要公共搜索引擎中实现这一点的公司,为其令人印象深刻且高度具体的特色片段提供支持。
这种范式改变了游戏规则,因为尽管法学硕士可以记住事实,但他们是根据训练数据“信息锁定”的。例如,ChatGPT 的信息历来仅限于 2021 年 9 月的信息截止日期。
RAG 模型允许考虑新信息以改进输出。这就是您在使用 Bing 搜索功能或在 ChatGPT 插件(如 AIPRM)中进行实时爬网时所做的事情。
这种范例也是使用法学硕士生成更强大内容输出的最佳方法。我预计,随着该方法的知识变得越来越普遍,当他们为客户生成内容时,会有更多人遵循我们在我的机构所做的事情。
RAG 是如何运作的?
想象一下,您是一名正在撰写研究论文的学生。您已经阅读了有关您的主题的许多书籍和文章,因此您拥有广泛讨论该主题的背景,但您仍然需要查找一些具体信息来支持您的论点。
您可以像研究助理一样使用 RAG:您可以给它一个提示,它会从其知识库中检索最相关的信息。然后,您可以使用此信息来创建更具体、风格更准确且不那么乏味的输出。法学硕士允许计算机根据概率返回广泛的响应。RAG 使该响应更加精确并引用其来源。

具有知识库的 RAG

带有知识图谱的 RAG
RAG 实现由三个组件组成:
- 输入编码器:该组件将输入提示编码为一系列向量嵌入,以供下游操作。
- 神经检索器:该组件根据编码的输入提示从外部知识库检索最相关的文档。当文档被索引时,它们会被分块,因此在检索过程中,只有最相关的文档和/或知识图段落才会被附加到提示中。换句话说,搜索引擎给出要添加到提示中的结果。
- 输出生成器:该组件考虑编码的输入提示和检索的文档,生成最终的输出文本。这通常是基础法学硕士,如 ChatGPT、Llama2 或 Claude。
为了让这个问题变得不那么抽象,请考虑一下 ChatGPT 的 Bing 实现。当您与该工具交互时,它会接受您的提示,执行搜索以收集文档并将最相关的块附加到提示并执行它。
所有三个组件通常都是使用预先训练的 Transformer 来实现的,Transformers 是一种神经网络,已被证明对于自然语言处理任务非常有效。如今,Google 的 Transformer 创新再次为 NLP/U/G 的全新世界提供了动力。很难想象这个领域有什么没有谷歌大脑和研究团队的印记。
输入编码器和输出生成器针对特定任务进行微调,例如回答问题或摘要。神经检索器通常不进行微调,但可以在大型文本和代码语料库上对其进行预训练,以提高其检索相关文档的能力。

RAG 通常使用向量索引或知识图中的文档来完成。在许多情况下,知识图(KG)是更有效和高效的实现,因为它们将附加数据限制为事实。
KG 和 LLM 之间的重叠表明了一种共生关系,可以释放两者的潜力。由于许多工具都使用知识图谱,现在是开始考虑利用知识图谱的好时机,而不仅仅是一种新颖的东西或我们只是向谷歌提供数据来构建的东西。
RAG 的陷阱
RAG 的好处非常明显;通过扩展语言模型可用的知识,您可以以自动化的方式获得更好的输出。也许不太明显的是仍然可能出错的地方以及原因。让我们深入研究一下:
检索是“成败”时刻
看,如果 RAG 的检索部分不正确,我们就有麻烦了。这就像派人去 Barclay Prime 买一份美味的芝士牛排,而他们回来时却带来了 Subway 的素食三明治——而不是你想要的。
如果它带回了错误的文件或跳过了黄金,那么你的输出将会有点——好吧——平淡无奇。仍然是垃圾进,垃圾出。
一切都与这些数据有关
这个范式有一点依赖性问题——而且都与数据有关。如果您正在使用像 MySpace 一样过时的数据集,或者只是没有达到目标,那么您就限制了该系统的功能。
回声室警报
深入研究这些检索到的文档,您可能会看到一些似曾相识的感觉。如果存在重叠,那么该模型听起来就像一位朋友在每次聚会上都讲述相同的故事。
您的结果会出现一些冗余,并且由于 SEO 是由模仿内容驱动的,因此您可能会得到未经充分研究的内容来通知您的结果。
提示长度限制
提示只能这么长,虽然您可以限制块的大小,但它可能仍然像试图将碧昂斯最新世界巡演的舞台放入迷你库珀中。迄今为止,只有 Anthropic 的 Claude 支持 100,000 个 token 上下文窗口。GPT 3.5 Turbo 最高发行量为 16,000 个代币。
脱离剧本
即使你付出了巨大的检索努力,这并不意味着法学硕士会坚持照本宣科。它仍然会产生幻觉并出错。
我怀疑这些是谷歌没有更早采取这项技术的一些原因,但既然他们最终加入了游戏,我们就来谈谈它。
什么是搜索生成体验 (SGE)?
许多文章将从消费者的角度告诉您什么是 SGE,包括:
- 如何为 Google SGE 做准备:SEO 成功的可行技巧
- Google SGE 将如何影响您的流量 – 以及 3 个 SGE 恢复案例研究
- 两个片段的故事:SGE 中的链接归因告诉我们有关搜索的哪些信息
- Google SGE 快照轮播:B2C、B2B 领域的 4 个获胜 SEO 策略
在本次讨论中,我们将讨论 SGE 如何成为 Google 的 RAG 实现之一;巴德是另一个。
(侧边栏:自推出以来,Bard 的输出已经变得更好了。您可能应该再试一次。)

SGE UX 仍然在不断变化。当我写这篇文章时,谷歌已经做出了一些改变,以削弱“显示更多”按钮的体验。
让我们把注意力集中在 SGE 的三个方面,这三个方面将显着改变搜索行为:
查询理解
从历史上看,搜索查询仅限于 32 个单词。因为文档是根据这些术语中 2 到 5 个单词的短语的交叉发布列表以及这些术语的扩展来考虑的,
谷歌并不总是理解查询的含义。谷歌表示 SGE 更擅长理解复杂查询。
人工智能快照
AI 快照是特色片段的更强大形式,带有生成文本和引文链接。它通常占据整个首屏内容区域。
后续问题
后续问题将 ChatGPT 中上下文窗口的概念带入搜索中。当用户从最初的搜索转向后续的后续搜索时,页面的考虑范围会根据先前结果和查询创建的上下文相关性而缩小。
所有这些都背离了搜索的标准功能。随着用户习惯这些新元素,行为可能会发生重大转变,因为谷歌专注于降低搜索的“ Delphic 成本”。毕竟,用户总是想要答案,而不是 10 个蓝色链接。
Google 的搜索生成体验如何运作(REALM、RETRO 和 RARR)
市场认为,谷歌在 2023 年初建立了 SGE,作为对 Bing 的回应。然而,谷歌研究团队在 2020 年 8 月发表的论文《检索增强语言模型预训练(REALM)》中提出了 RAG 的实现。
该论文讨论了一种使用 BERT 流行的掩码语言模型(MLM)方法,使用带有语言模型的文档语料库进行“开卷”问答的方法。

REALM 识别完整文档,找到每个文档中最相关的段落,并返回单个最相关的段落以进行信息提取。
在预训练期间,REALM 被训练为预测句子中的屏蔽标记,但它也被训练为从语料库中检索相关文档并在进行预测时关注这些文档。这使得 REALM 能够学习生成比传统语言模型更准确、信息更丰富的文本。
谷歌的 DeepMind 团队随后通过检索增强型变压器(RETRO)进一步发展了这个想法。RETRO是一种与REALM类似的语言模型,但它使用不同的注意力机制。
RETRO 以更加分层的方式处理检索到的文档,这使得它能够更好地理解文档的上下文。这使得文本比 REALM 生成的文本更加流畅和连贯。
继 RETRO 之后,团队开发了一种名为“ Retrofit Attribution using Research and Revision”(RARR)的方法,以帮助验证和实施 LLM 的输出并引用来源。

RARR 是一种不同的语言建模方法。RARR 不会从头开始生成文本。相反,它从语料库中检索一组候选段落,然后对它们重新排序以选择适合给定任务的最佳段落。这种方法允许 RARR 生成比传统语言模型更准确、信息更丰富的文本,但计算成本可能更高。
RAG 的这三种实现都有不同的优点和缺点。虽然正在生产的内容可能是这些论文等中所代表的创新的某种组合,但其想法仍然是搜索文档和知识图并与语言模型一起使用以生成响应。
根据公开共享的信息,我们知道 SGE 使用PaLM 2 和 MuM语言模型的组合以及 Google 搜索的某些方面作为其检索器。这意味着谷歌的文档索引和知识库都可以用来微调响应。
Bing 首先实现了这一目标,但凭借 Google 在搜索领域的实力,没有任何组织有资格使用这种范例来呈现和个性化信息。
搜索生成体验的威胁
Google 的使命是整合全球信息并使其可供访问。从长远来看,也许我们会像记忆迷你光盘和双向寻呼机一样回顾这 10 个蓝色链接。正如我们所知,搜索可能只是我们获得更好结果之前的一个中间步骤。
ChatGPT最近推出的多模式功能是 Google 工程师经常表示他们想要成为的“星际迷航”计算机。搜索者一直想要答案,而不是审查和解析选项列表的认知负担。
最近一篇题为“定位搜索”的观点论文挑战了这一观点,指出用户更喜欢进行研究和验证,而搜索引擎已经向前推进。
因此,这就是可能发生的结果。
搜索需求曲线的重新分布
当用户不再使用由新话组成的查询时,他们的查询将会变得更长。
当用户意识到谷歌能够更好地处理自然语言时,它将改变他们搜索的措辞方式。头部术语将会缩小,而粗略的中段和长尾查询将会增长。

CTR模型将会改变
10 个蓝色链接的点击次数将会减少,因为 AI 快照会将标准有机结果推低。位置 1 30-45% 的点击率 (CTR) 可能会急剧下降。
然而,我们目前没有真实的数据来表明分布将如何变化。因此,下面的图表仅用于说明目的。

排名跟踪将变得更加复杂
一段时间以来,排名跟踪工具必须为各种功能呈现 SERP。现在,这些工具每个查询都需要等待更多时间。
大多数 SaaS 产品都构建在 Amazon Web Service (AWS)、Google Cloud Platform (GCP) 和 Microsoft Azure 等平台上,这些平台根据使用的时间收取计算成本。
虽然渲染结果可能会在 1-2 秒内返回,但现在可能需要等待更长时间,从而导致排名跟踪的成本增加。
上下文窗口将产生更加个性化的结果
后续问题将为用户提供“选择你自己的冒险”式的搜索旅程。随着上下文窗口变窄,一系列高度相关的内容将填充旅程,否则每个人都会产生更模糊的结果。
实际上,搜索变得多维,内容创建者有责任使其内容满足多个阶段以保留在考虑范围内。

在上面的示例中,Geico 希望内容与这些分支重叠,以便当用户在其旅程中前进时它们保留在上下文窗口中。
确定您的 SGE 威胁级别
我们没有关于 SGE 环境中用户行为如何变化的数据。如果您这样做,请联系我们(看着您,SimilarWeb)。
我们所拥有的是对用户搜索行为的一些历史了解。
我们知道,用户平均需要 14.66 秒来选择搜索结果。这告诉我们,用户不会等待生成时间超过14.6秒的自动触发的AI快照。因此,超出该时间范围的任何内容都不会立即威胁您的自然搜索流量,因为用户只会向下滚动到标准结果而不是等待。

我们还知道,从历史上看,特色片段出现在 SERP 中时捕获了 35.1% 的点击次数。

这两个数据点可用于提供一些假设,以构建一个模型,说明此次推出可能会损失多少流量。
我们首先根据现有数据回顾一下 SGE 的状况。
上海黄金交易所的现状
由于 SGE 上没有数据,如果有人创建一些数据那就太好了。我碰巧在 SGE 中发现了包含大约 91,000 个查询及其 SERP 的数据集。
对于每个查询,数据集包括:
- 查询:执行的搜索。
- 初始 HTML:SERP 首次加载时的 HTML。
- 最终 HTML:AI 快照加载后的 HTML。
- AI快照加载时间:AI快照加载需要多长时间。
- 自动触发:快照是自动触发还是必须单击“生成”按钮?
- AI快照类型:AI快照是信息性的、购物性的还是本地性的?
- 后续问题:后续问题列表。
- 轮播 URL:AI 快照中显示的结果的 URL。
- 前 10 个有机结果:前 10 个 URL,以查看重叠情况。
- 快照状态:是否有快照或生成按钮?
- “显示更多”状态:快照是否需要用户单击“显示更多”?
查询也被分为不同的类别,因此我们可以了解不同事物的执行情况。我没有足够的注意力来浏览整个数据集,但这里有一些顶级发现。
AI 快照现在平均需要 6.08 秒生成

当 SGE 首次启动时,我开始检查 AI 快照的加载时间,它们花了 11 到 30 秒才出现。现在我看到加载时间范围为 1.8 到 17.2 秒。自动触发的 AI 快照加载时间为 2.9 至 15.8 秒。
从图表中可以看出,此时大多数加载时间远低于 14.6 秒。很明显,绝大多数查询的“10 个蓝色链接”流量将受到威胁。

根据关键词类别的不同,平均值略有不同。由于娱乐-体育类别的加载时间比所有其他类别长得多,这可能是每个给定垂直领域的页面源内容通常有多重的函数。
快照类型分布

虽然体验有很多变体,但我将快照类型大致分为信息、本地和购物页面体验。在我的 91,000 个关键字集中,细分为 51.08% 信息性、31.31% 本地性和 17.60% 购物性。
60.34% 的查询没有 AI 快照

在解析页面内容时,数据集会识别两种情况来验证页面上是否存在快照。它会查找自动触发的快照和“生成”按钮。查看此数据表明,数据集中 39.66% 的查询触发了 AI 快照。
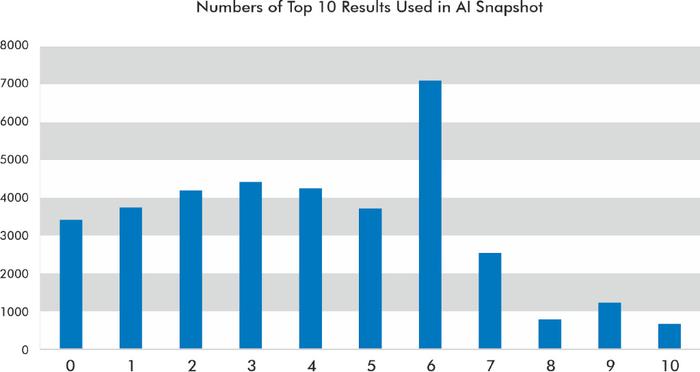
经常使用前 10 个结果,但并不总是使用
在我查看的数据集中,位置 1、2 和 9 在 AI 快照的轮播中被引用最多。

AI 快照最常使用前 10 个结果中的 6 个来构建其响应。然而,9.48% 的情况下,它不会使用 AI 快照中前 10 个结果中的任何一个。
根据我的数据,它很少使用前 10 名的所有结果。
高度相关的块通常出现在轮播中的较早位置
让我们考虑查询 [bmw i8] 的 AI 快照。该查询在轮播中返回七个结果。其中四个在引文中被明确引用。

点击轮播中的结果通常会将您带到“ fraggles ”(才华横溢的辛迪·克鲁姆(Cindy Krum)创造的段落排名链接术语)之一,这些链接会将您带到特定的句子或段落。

言外之意是,这些是为人工智能快照提供信息的段落或句子。
当然,我们的下一步是尝试了解这些结果的排名方式,因为它们的呈现顺序与副本中引用的 URL 的顺序不同。
我认为这个排名更多的是关于相关性而不是其他任何事情。

为了测试这个假设,我使用通用句子编码器对段落进行矢量化,并将它们与矢量化查询进行比较,看看降序是否成立。
我预计相似度得分最高的段落将是轮播中的第一个段落。

结果并不完全符合我的预期。也许可能存在一些查询扩展,我正在比较的查询与 Google 可能正在比较的查询不同。
不管怎样,这个结果足以让我进一步研究这个问题。将输入段落与生成的快照段落进行比较,第一个结果是明显的相关性获胜者。

第一个结果中使用的块与 AI 快照段落最相似,在我抽查过的一堆结果中都得到了验证。
因此,在我看到其他证据之前,排名在有机结果的前 2 名并拥有最相关的内容段落是进入 SGE 轮播中第一个位置的最佳方式。
计算您的 SGE 威胁级别
缺乏完整数据很少成为不评估业务环境风险的理由。许多品牌希望估算出当 SGE 广泛使用时他们可能会损失多少流量。
为此,我们建立了一个模型来确定潜在的流量损失。顶层方程非常简单:

我们仅对具有 AI 快照的关键字进行计算。因此,该公式的更好表示如下。

调整后的点击率是大部分奇迹发生的地方,正如孩子们所说,达到这一目标需要“数学”。
我们需要考虑 SERP 相对于页面类型呈现的各种方式,无论它是否自动触发,或者是否显示“显示更多”按钮。

简而言之,我们根据人工智能快照的存在和加载时间确定每个关键字的调整后点击率,预计购物结果的威胁最大,因为它是全页体验。
我们调整后的点击率指标是分布因子中表示的参数的函数。

分布因子是AI快照中轮播链接、引文链接、购物链接和本地链接的加权影响。
该因素根据这些元素的存在而变化,并允许我们考虑目标域是否存在于任何这些特征中。

对于非客户,我们使用非品牌关键字(其中 Semrush 中的流量百分比非零)以及来自 Advanced Web Ranking 的点击率研究的垂直特定点击率来运行这些报告。
对于客户,我们使用所有带来 80% 点击次数的关键字以及 Google Search Console 中他们自己的点击率模型来执行相同的操作。
例如,根据 Nerdwallet(而非客户端)的热门流量驱动关键字进行计算,数据显示“受保护”威胁级别,潜在损失为 30.81%。对于一个主要通过联属网络营销收入盈利的网站来说,这在他们的现金流中是一个相当大的缺口。

这使我们能够根据客户当前在 SGE 中的显示情况为客户制定威胁报告。我们计算潜在的交通损失,并按照从低到严重的等级对其进行评分。
客户发现重新平衡关键字策略以减少损失很有价值。如果您有兴趣获得自己的威胁报告,请告诉我们。
认识 Raggle:SGE 的概念证明
当我在 Google I/O 上第一次看到 SGE 时,我就迫不及待地想尝试一下。直到几周后它才公开可用,所以我开始构建我自己的版本。大约在同一时间,JSON SERP 数据提供商AvesAPI的优秀人员向我伸出援手,向我提供了他们的服务试用版。
我意识到我可以利用他们的服务和Llama Index的 LLM 应用程序开源框架来快速启动 SGE 工作方式的版本。

这就是我所做的。它称为 Raggle。
不过,让我稍微管理一下你的期望,因为我是本着研究的精神而不是与一个由 50,000 名世界级工程师和博士组成的团队建立这个项目的。下面是它的缺点:
- 速度非常慢。
- 它没有反应。
- 它仅进行信息响应。
- 它不会填充后续问题。
- 当我的 AvesAPI 积分用完时,新查询将停止工作。
也就是说,我添加了一些彩蛋和其他功能来帮助了解 Google 如何使用 RAG。
拉格尔的工作原理

Raggle 实际上是 SERP API 解决方案之上的 RAG 实现。
在运行时,它将查询发送到 AvesAPI 以获取 SERP。我们会在 SERP HTML 返回后立即向用户显示,然后开始并行抓取前 20 个结果。
从每个页面提取内容后,它会添加到 Llama Index 中的索引中,其中包含 URL、页面标题、元描述和 og:images 作为每个条目的元数据。
然后,使用提示来查询索引,其中包括用户的原始查询以及用 150 个单词回答查询的指令。矢量索引中的最佳结果块将附加到查询中,并发送到 GPT 3.5 Turbo API 以生成 AI 快照。
从文档创建索引并查询它只需三个语句:
index = VectorStoreIndex.from_documents(documents) query_engine = CitationQueryEngine.from_args( index, # here we can control how many citation sources similarity_top_k=5, # here we can control how granular citation sources are, the default is 512 citation_chunk_size=155, ) response = query_engine.query("Answer the following query in 150 words: " + query)
使用 Llama Index 提供的引用方法,我们可以检索文本块及其元数据来引用来源。这就是我能够以与 SGE 相同的方式在输出中显示引用的方式。
finalResponse["citations"].append({ 'url': citation.node.metadata.get('url', 'N/A'), 'image': citation.node.metadata.get('image', 'N/A'), 'title': citation.node.metadata.get('title', 'N/A'), 'description': citation.node.metadata.get('description', 'N/A'), 'text': citation.node.get_text() if hasattr(citation.node, 'get_text') else 'N/A', 'favicon': citation.node.metadata.get('favicon', 'N/A'), 'sitename' : citation.node.metadata.get('sitename', 'N/A'), })
继续尝试吧。当您单击右侧的三个点时,它会打开块资源管理器,您可以在其中看到用于通知 AI 快照响应的块。
在此概念验证实现中,您将注意到查询与块的相关性计算与结果在轮播中显示的顺序的一致程度。
我们生活在搜索的未来

我在搜索领域工作了近二十年。在过去 10 个月里,我们看到的变化比我整个职业生涯中看到的变化还要多——我说的是经历了佛罗里达、熊猫和企鹅的更新。
一系列的变革带来了许多利用新技术的机会。信息检索和 NLP/NLU/NLG 领域的研究人员非常乐意公布他们的发现,使我们能够更清楚地了解事物的实际工作原理。
现在是了解如何将 RAG 管道构建到 SEO 用例中的好时机。
然而,谷歌在多个方面都受到攻击。
- 抖音。
- 聊天GPT。
- 美国司法部。
- 用户对搜索质量的看法。
- 生成人工智能内容的洪流。
- 市场上问答系统的版本众多。
最终,所有这些对 Google 的威胁都是对来自 Google 的流量的威胁。
有机搜索格局正在发生有意义的变化,并且变得越来越复杂。随着用户满足信息需求的形式不断破碎,我们将从针对网络的优化转向针对大型语言模型的优化,并在这种环境中实现结构化数据的真正潜力。
就像网络上的大多数机会一样,最早抓住这些机会的人将获得丰厚的回报。









