

麻省理工学院的研究人员近日开发了一套会玩“阿瓦隆(Avalon)”桌游的 AI 系统,名为 DeepRole。它可以在遵守所有游戏规则的前提下,在阿瓦隆多人在线游戏网站 ProAvalon.com 上跟 0-4 名人类玩家同场竞技,有些是它的队友,有些则是对手。
在超过 4000 多场游戏中,无论所处哪个阵营,队友是 AI 还是人类,DeepRole 取得的平均胜率都超过了人类玩家。而且数据统计显示,如果用 AI 替换一名人类玩家,所处阵营的胜率最高可以提高 12%。虽然被替换玩家的游戏水平不详,但超过 10% 的稳定胜率提升说明 AI 的表现已经超出了普通玩家。
这项研究是一个更广泛的项目的一部分,该项目旨在更好地模拟人类如何依据社会反应做出决定,从而帮助开发能够更好地理解、学习人类,并与人类合作的机器人。
在下个月的神经信息处理系统大会(NeurIPS)上,麻省理工学院研究团队将进一步展示 DeepRole。目前研究成果已经以预印本的形式发表在 Arxiv 上。
图 | ProAvalon.com 的游戏界面(来源:YouTube)
“阿瓦隆”的游戏规则
桌游“阿瓦隆”的全称是“抵抗组织:阿瓦隆(The Resistance: Avalon)”,类似于“狼人杀”。一局游戏由 5-10 人组成,每人有一张身份牌、一张成功票和一张失败票。所有人被划分为抵抗组织和间谍两个相互对立的阵营。前者希望任务成功,后者希望任务失败。
每局游戏共有 5 轮任务,玩家们轮流担任队长,负责指派 3-5 个人行使投票权,决定该轮任务成功与否。只要有一张失败票,该任务就算失败。
游戏的核心角色是抵抗组织阵营的“梅林(Merlin)”和间谍阵营的“刺客(Assassin)”。“梅林”知道谁是间谍,因此可以不让他们执行任务,确保任务 100% 成功,但也不能做的太明显,将身份暴露给间谍阵营会引来“刺客”的刺杀。
抵抗组织阵营的玩家在执行任务时只能投成功票,获胜条件是三轮任务成功。而间谍阵营玩家可以视情况投失败票或成功票(隐藏身份),获胜条件是三轮任务失败或完成对“梅林”的刺杀(正确找出“梅林”是谁)。
这是一种明显的信息不对称游戏,考验玩家在短时间内收集信息并加以分析和推理的能力。
对于 AI 来说,想要玩好这类游戏,最难的一环就是如何区分阵营,尤其是在玩家会刻意隐藏身份的前提下找出谁是队友,谁是对手。
“人类向他人学习并与之合作,使我们能够共同实现一个人无法独立完成的事情,”研究团队成员 Max Kleiman-Weiner 表示,“像『阿瓦隆』这样的游戏可以更好地模仿人们在日常生活中所经历的动态社交环境。无论在幼儿园还是职场,我们都必须弄清楚哪些人与自己一组,可以一起共事。”

DeepRole 的设计原理
研究团队出于概念验证的原因稍微简化了游戏,DeepRole 被限定在 5 人局中,因为拥有特殊能力的角色会随着人数的增加而增加,使游戏的不确定性和复杂程度大幅上升,但其他规则没有任何变化。
在开发 DeepRole 的过程中,研究人员使用了一种常见的“反事实遗憾最小化(CFR)”的游戏计划算法,通过反复与自己对战来学习游戏,同时还引入了演绎推理(Deductive Reasoning)的技巧,使其具备从已有假设或前提推导出新结论的能力,比如 AI 看到任务中出现了一张失败票,就能推断出必然至少有一名间谍的结论。
在游戏中,CFR 会前瞻性地创建由线和节点组成的“游戏决策树”,整合了每个玩家在未来每个决策点可能采取的所有动作,以描述每个玩家可能做出的举动。
在进行数十亿次的游戏模拟时,CFR 会注意哪些动作增加或减少了获胜的机会,反复修改其策略以包含更多的好决策,最终选择最优解。
虽然与围棋或者扑克相比,“阿瓦隆”的游戏规则并不复杂,但由于每轮任务都可以选择不同的几个人,而且通过集体投票表决还可以最多否决五次队长的提议,因此在一局游戏中,其状态空间包含 10^56 组不同的信息集,甚至超过了国际象棋的状态空间(10^47)。
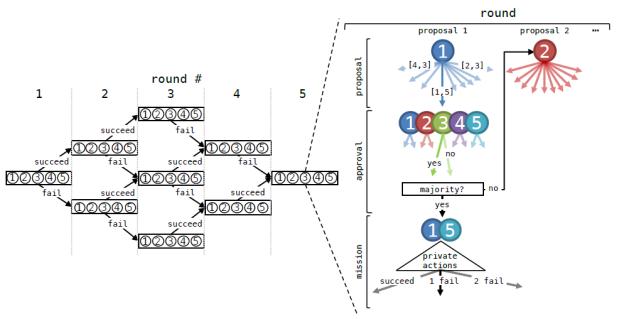
图 | DeepRole 的决策树和推断流程图(来源:MIT)
为了缩小决策树的尺寸,优化寻找最优解的过程,研究团队还开发了价值网络,配合 CFR 共同使用。
在训练过程中,DeepRole 没有借助任何人类玩家的数据,仅通过自己扮演两个阵营的角色来“左右互搏”。它会通过决策树来预测每个玩家将要做什么,每一个分支都代表着玩家的不同策略,而树上的每个节点都有对应的价值,是 AI 对选择这条策略的预估回报。
理论上,一条分支的整体价值越高,意味着对应阵营的获胜的可能性就越大。
在游戏的执行任务环节,DeepRole 会以自己阵营为基础,用决策树中的选择对比每个玩家的真实选择。如果玩家做出的选择和 AI 预期的不一样,那么该玩家就可能是在对立阵营。随着游戏的进行,它会积累更多的数据,对玩家身份的判断也会更加准确。最终,这些概率信息会用于更新 AI 的策略,以增加其获胜机会。
与此同时,AI 还会使用相同的技术来估计第三人视角的观察者如何看待自己的行为。这有助于判断其他玩家的反应,从而做出更明智的决策。
“如果一个两人执行的任务失败,那么合理的推断是其中至少有一名间谍。AI 未来很可能不会在同一任务中同时带上这两人,因为它知道其他抵抗组织阵营的玩家会觉得这个提议很糟糕,”论文的第一作者 Jack Serrino 解释道。他也是狂热的“阿瓦隆”游戏爱好者。
玩法高端,胜率不俗,还不用沟通
在真实测试中,从未跟人类一起练习的 DeepRole 表现不俗。
在一局玩家上传的视频中,AI 扮演的“梅林”甚至懂得高端玩法:人类玩家在后期判断出了哪三个人是好人(抵抗组织),于是派这三个人执行任务,“梅林”在明知道这三人出任务绝对安全的情况下,依然不断否决提议,以混淆间谍的判断,让他们分不清谁是“梅林”,最终成功避免被刺杀。
超过 4000 场的游戏统计数据显示,在一局有 5 名人类玩家的游戏中,如果用 AI 替换其中之一,其所处阵营的平均胜率会比替换前高出约 12%。反之,在一局有 5 个 AI 的游戏中,如果用人类玩家替换其中之一,其阵营的平均胜率则会下降约 8%。
尽管玩家水平参差不齐,没有一个衡量标准,但超过 10% 的胜率差距的确能体现出 DeepRole 的表现不俗。
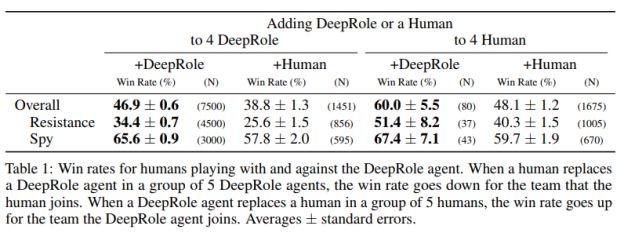
图 | 在不同阵营,DeepRole 和人类的胜率对比(来源:MIT)
值得一提的是,DeepRole 在游戏过程中不会与其他玩家交流,依旧能取得不错的成绩。通常来说,沟通是“阿瓦隆”等桌游的关键组成部分。在游戏中,人类玩家可以通过游戏平台的文字框相互交流。
“但事实证明,仅凭观察玩家的行为,AI 就能够与其他人很好地合作。这很有趣,因为人们倾向于认为这样的游戏需要复杂的沟通策略,”Kleiman-Weiner 表示。
接下来,研究团队将尝试让 DeepRole 使用简单的文字进行交流,例如给出自己对玩家阵营的看法——这些信息已经以概率的形式存在于 AI 的决策树当中了,但需要按照概率配上正确的文字。
除此之外,他们还想让 DeepRole 学习更强调沟通、社交和推理的“狼人杀”。这对沟通能力提出了更高的要求,因为它需要学习如何争论并说服其他玩家,涉及到的推理因素也更复杂。
“在这类游戏中,还有很多难点需要克服,但沟通绝对是最关键的因素,”Serrino 强调。









