




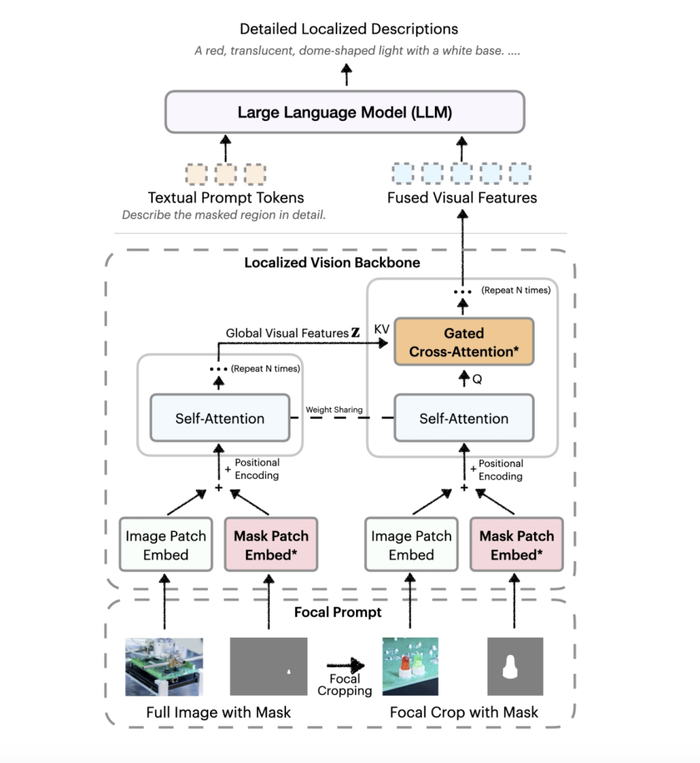
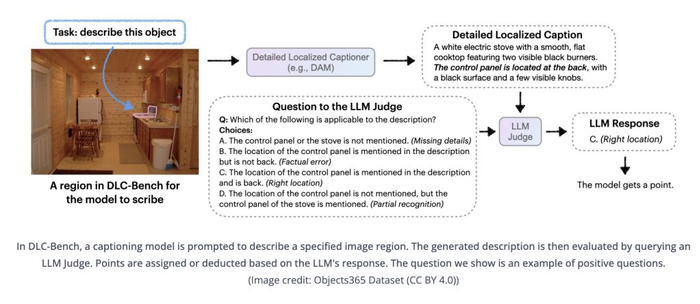
【#英伟达推DAM3B模型#:突破局部描述难题,让 AI 看懂图像 / 视频每一个角落】4 月 24 日消息,科技媒体 marktechpost 昨日(4 月 23 日)发布博文,报道称英伟达为应对图像和视频中特定区域的详细描述难题,最新推出了 Describe Anything 3B(DAM-3B)AI 模型。视觉-语言模型(VLMs)在生成整体图像描述时表现出色,但对特定区域的细致描述往往力不从心,尤其在视频中需考虑时间动态,挑战更大。
英伟达推出的 Describe Anything 3B(DAM-3B)直面这一难题,支持用户通过点、边界框、涂鸦或掩码指定目标区域,生成精准且贴合上下文的描述文本。DAM-3B 和 DAM-3B-Video 分别适用于静态图像和动态视频,模型已在 Hugging Face 平台公开。

特别声明:以上文章内容仅代表作者本人观点,不代表新浪网观点或立场。如有关于作品内容、版权或其它问题请于作品发表后的30日内与新浪网联系。
11条评论|1,033人参与网友评论

表情
登录|注册
|退出
分享到微博
发布最热评论

可爱的小麦苗呦黑龙江齐齐哈尔
现在的科技可真是发展的越来越好,越来越给力
4月24日19:41举报赞1,008回复

小岛楸树yb湖北武汉
这配置真的很难不让人心动啊 真的很不错
4月24日19:42举报赞6回复

爱学习却不想学习的小朋友山西晋中
敢于直面难题就很厉害呀!一定可以更好
4月24日19:42举报赞4回复
最新评论

香香的汉堡呀四川成都
这样的技术的确是很不错,一起来看看吧
4月24日19:52举报赞回复

怑槑怑萌怑呦稚F贵州六盘水
科技发展的越来越好了,给大家也带来了很多便利
4月24日19:44举报赞回复

结束不回头不将就湖南
不得不说现在的这些科技配置也是挺牛的呀。
4月24日19:44举报赞回复
查看全部11条评论 >










