




大语言模型(LLMs)作为语言理解与生成的基础技术,其应用已扩展至语音处理领域,如语音识别、对话系统等新兴方向。然而,构建基于LLMs的语音对话系统面临核心挑战:真实多语种对话数据的稀缺性。这类数据需涵盖自然停顿、说话者重叠等复杂交互场景,对提升AI系统的多语种理解能力和长上下文处理能力至关重要,直接影响下一代人机交互的自然度与准确性。为推动这一研究发展,由数据堂主办,中国移动、Meta、Google、 Samsung、Naver联合赞助的INTERSPEECH2025多语种对话语音语言模型(MLC-SLM)研讨会正式对外发布,本次研讨会将通过发布多语种对话语音数据集并举办MLC-SLM挑战赛,推动该领域的技术突破。

一、核心亮点
1. 双赛道任务,均要求参赛者探索基于 LLM 的语音模型的开发:
(1)任务I:多语种对话语音识别
① 目标:开发基于 LLM 的多语种 ASR 模型。
② 参赛者将获得每段对话的真实时间戳标注及说话者标签用于切分语音片段。
③ 该任务的重点是优化多语种对话环境下的语音识别准确率。
(2)任务II:多语种对话语音日志与识别
① 目标:开发一个同时进行说话者日志(即识别谁在何时说话),又能进行语音识别(将语音转换为文本)的系统。
② 评估过程中不提供任何先验信息,如真实时间戳标注、预先切分的语音片段、说话者标签等
③ 该任务可以使用基于级联系统或端到端系统的方法。
对于任务 I,系统性能将基于不同语言的词错误率(WER)或字符错误率(CER)进行评估。
对于任务 II,性能将基于说话人日志错误率(DER)以及连接最小排列词错误率(cpWER)或字符错误率(cpCER)进行评估。DER用于确定在参考标注和日志结果之间的最佳说话人排列。然后,将同一说话人识别结果和参考进行连接,以计算cpWER或cpCER。所有提交将根据cpWER或cpCER进行排名。
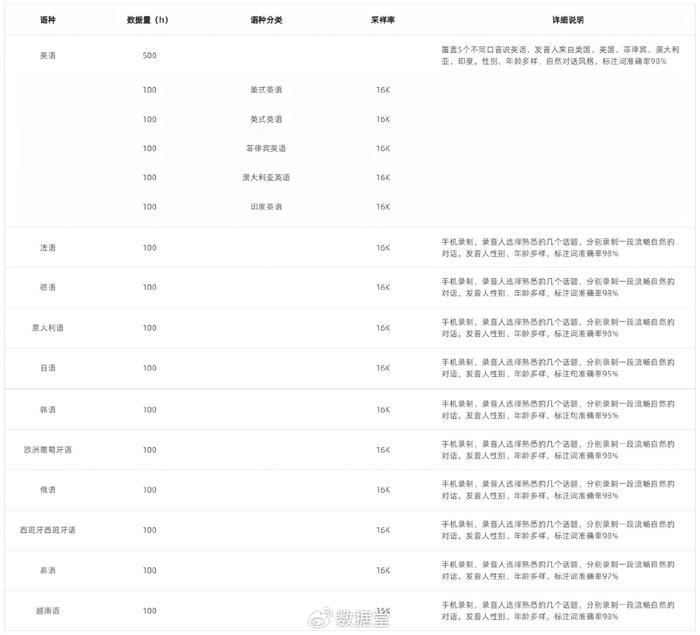
2. 多语种对话语音数据集
11种语言:英语(细分美/英/澳/印/菲口音)、法、德、日、韩等,总时长1500小时。
(1)数据特性:
① 自然对话场景:每段录音均由两位说话者就随机分配的主题进行有意义的对话,需提供真实时间戳标注和说话者标签。
② 高精度标注:日、韩语标注词准确率95%+,其他语言98%。
③ 多设备录制:使用iPhone等设备并于安静的室内环境采集,采样率16kHz。
(2)数据集结构:
① 训练集:英语500小时(分5种口音)+其他语言各100小时,任务I/II共享。
② 开发集:每语种约4小时,任务I/II共享。
③ 评估集:每个任务使用不同的评估集,分别指定为 Eval_1 和 Eval_2。具体来说,Eval_1 包括真实时间戳标注和说话者标签,使用 WER/CER 进行评估。Eval_2 不提供时间戳或说话者标签,因此需要使用说话者日志系统在识别之前对较长的录音进行分段。
参与者可以通过签署数据使用协议并提交至报名表单来访问数据集(具体详情可前往数据堂官网或公众号-DatatangBJ 查看)。提交后,数据下载链接将发送到您的电子邮件。
3. 学界与产业界双重背书
- 组委会:冯俊兰(IEEE Fellow及首席科学家/中国移动)、Eng-Siong Chng(教授/南洋理工大学)、Shinji Watanabe(副教授/卡内基梅隆大学)、Khalid Choukri(秘书长/欧洲语言资源协会)等全球顶尖专家领衔。
- 赞助商:中国移动、Meta、 Google、 Samsung、 Naver、数据堂
二、参赛价值
- 奖金池20,000美金:单任务前三名分别获5,000/3,000/2,000美金。
- 论文发表机会:优秀成果可入选INTERSPEECH研讨会,与顶级学者同台交流(参考下文“其他主题”)。
- 技术自由度:允许使用外部数据集与预训练模型(需公开声明),支持数据增强。
注:参加研讨会的注册费
·非会员注册费:60欧元
·非会员学生注册费:45欧元
·ISCA会员注册费:50欧元
·ISCA学生会员注册费:35欧元
三、关键日程(AOT时间)
2025 年 3 月 10 日:注册开放
2025 年 3 月 15 日:训练数据发布
2025 年 3 月 20 日:开发集和基线系统发布
2025 年 5 月 15 日:评估集发布及 Leaderboard开放
2025 年 5 月 30 日:Leaderboard冻结,论文提交系统(CMT)开放
2025 年 6 月 15 日:论文提交截止
2025 年 7 月 1 日:论文录用通知
2025 年 8 月 18 日:荷兰鹿特丹研讨会(鹿特丹阿霍伊会议中心)
四、参赛必读
所有参与者必须遵守以下规则:
·外部资源使用:对于任务I 和 任务II,允许使用外部数据集和预训练模型(包括语音基础模型和大语言模型)。所有使用的外部资源必须是公开可获取的,并且在最终系统报告中应明确标明。
·数据增强:允许在发布的训练集上进行数据增强,可能包括但不限于添加噪声或混响、速度扰动和音调修改。
·禁止使用评估集:严禁以任何形式使用评估集。这包括但不限于使用评估集进行微调或训练模型。
·多系统融合:参与者不得在任务I和任务II中使用系统融合。提交的结果必须来自单个模型,而不是通过结果融合得出。
·提交要求:所有参赛者必须提交其系统。提交内容包括最终识别结果、模型以及能够直接进行推理并获得最终结果的Docker容器等文件。详细的提交说明将在基线系统发布后提供。请注意,我们将公开那些确认参与但未提交任何文件的团队及其所属机构的名称。
·主办方解释权:主办方对本规则拥有最终解释权,特殊情况由主办方酌情协调解释。
五、其他主题
除了挑战系统内容外,还鼓励参与者提交创新发和前瞻性研究论文。主题包括但不限于:
·新颖的架构和算法:开发用于训练语音语言模型的新架构和算法。
·音频数据处理管线:创新音频数据处理流程,促进多样化互联网数据的收集,以便训练语音语言模型。
·自然且情感丰富的语音生成:设计用于生成更加自然且富有情感表达的对话语音的算法,提升对话系统的表现。
·利用多轮对话历史:利用多轮对话历史来增强识别和分离结果的技术
·评估技术和基准:评估语音语言模型的创新评估技术或基准。
·新数据集:创建用于训练语音和音频语言模型的新数据集,包括真实数据和合成数据。
六、立即参与
✅注册通道:参与者需进行注册。请上传已签署的数据使用协议并填写注册表单(谷歌表单)【需挂VPN方可点击注册】,挑战赛将于2025年3月10日开始。
如需了解其他与注册相关的信息,请发送邮件至:mlc-slmw@nexdata.ai
✅数据协议:已注册的参与者将有权访问训练和测试数据集。他们必须签署数据使用协议(见下文)、同意保密并遵守数据保护协议。数据集仅用于本次研讨会竞赛,严禁重新分发或任何其他用途。参与者有责任保护数据免受未经授权的访问。
数据许可协议:Data use agreement- nexdata【点击下载】
真实对话语音数据不仅对于技术进步至关重要,还在构建能够理解多语种和长上下文内容的人工智能系统方面发挥关键作用。本次研讨会通过发布高质量的多语种对话语音数据集,并举办MLC-SLM挑战赛,旨在为全球研究者和开发者提供一个开放的平台,促进该方向的研究。未来,随着更多创新技术的涌现,基于LLMs的语音对话系统将更加智能、贴近人类交流方式,为全球用户提供无缝的多语言沟通体验。让我们携手共进,开启人机交互的新篇章!












