

了解更多!」
学生时代,想必你肯定听过巴甫洛夫和狗的故事:
每次给狗喂食之前,都先摇动一个铃铛。久而久之,狗学会了把铃铛当做进食的前奏。后来,只要铃铛一响,狗就会开始流口水,不管接下来有没有食物。这表明它们已经学会了“预测奖励”。
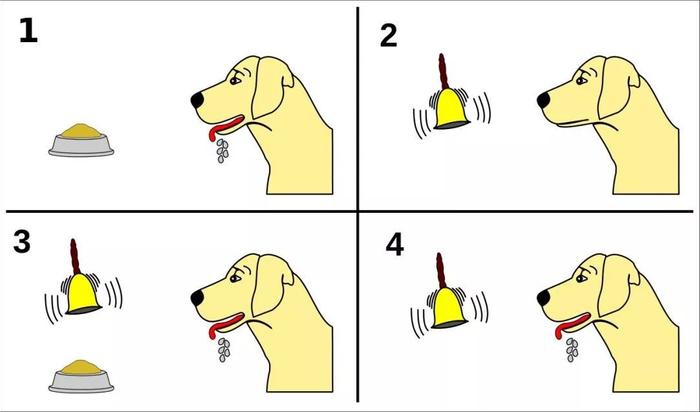
在最初的实验中,巴甫洛夫通过测量它们产生的唾液量来估计它们的期望。但最近几十年来,科学家们开始破译大脑学习这些预测的方式。
同时,计算机科学家开发了在AI系统中进行强化学习的算法。这些算法使AI系统无需外部指导即可学习复杂的策略,学习过程由奖励预测机制指导。
DeepMind的一项新研究表明,对于破译大脑的内部运作方式,或许AI才是我们的老师。

在这项刚刚被发表在Nature的研究中,DeepMind与哈佛大学的研究人员受最近关于分布强化学习的AI研究启发,提出了一种基于多巴胺的强化学习的方法。
他们认为:和AI系统类似,大脑不是以“平均值”的方式预期未来可能的回报,而是以“概率分布”的方式来预期,从而证明大脑中存在“分布强化学习”。
大脑进行强化学习,类似于顶级AI算法
“大脑中的多巴胺是一种代表惊讶(surprise)的信号。”论文一作Will Dabney说: “当情况好于预期时,就会释放出更多的多巴胺。”

Will Dabney
以前认为,这些多巴胺神经元反应都相同。但是研究人员发现,各个多巴胺神经元似乎有所不同:每个神经元“快乐”或“悲伤”的程度是不一样的。
“更像是合唱团,它们唱着不同的音符,相互协调,”Dabney说。
大脑中的多巴胺
这一发现从一种称为分布强化学习的过程中获得了灵感。没错,就是AI用来掌握围棋和星际争霸2等游戏的技术之一。
最简单的说,强化学习是一种奖励,它可以强化让它有所得的行为。这需要了解当前的行动如何导致未来的回报。例如,一条狗可能会学习命令“ 坐”,因为当它这样做时会得到奖励。
以前,AI和神经科学中的强化学习模型都专注于学习以预测“平均”的未来回报。“但这并不能反映现实情况,”Dabney说。
他还举了个例子:“例如,当有人玩彩票时,他们期望赢或输,但是他们并不会期望中间结果。”
当未来不确定时,可能的结果可以用概率分布来表示:有的是正的,有的是负的。使用分布强化学习算法的AI能够预测可能的奖励的全部范围。
为了测试大脑的多巴胺奖励途径是否也通过分布起作用,该团队记录了小鼠中单个多巴胺神经元的反应。他们训练小鼠完成一项任务,并给予它们大小不同且不可预测的奖励。
研究人员发现,不同的多巴胺细胞确实表现出不同程度的惊讶。也就是说,AI算法让我们知道了应该在神经反应中寻找什么。
接下来,新智元为大家剖析这项研究的来龙去脉。
时间差(DT)学习算法:完善强化学习预测链
强化学习是将神经科学和AI相联系的最古老,最有力的想法之一。早在1980年代后期,计算机科学研究人员试图开发一种算法,该算法仅使用“奖惩”作为信号,学习如何独自执行复杂的行为。
这种奖励机制的预测与人类自身的一些行为很类似,比如,学生努力学习来应对考试,其奖励回报是考试成绩可能会更高。总体而言,预测当前行为的未来回报,是这种算法的核心机制。
解决奖励预测问题的一个重要突破是时间差学习(TD)算法,该算法不会去计算未来的总回报,而只是尝试在下一个时刻预测即时奖励。
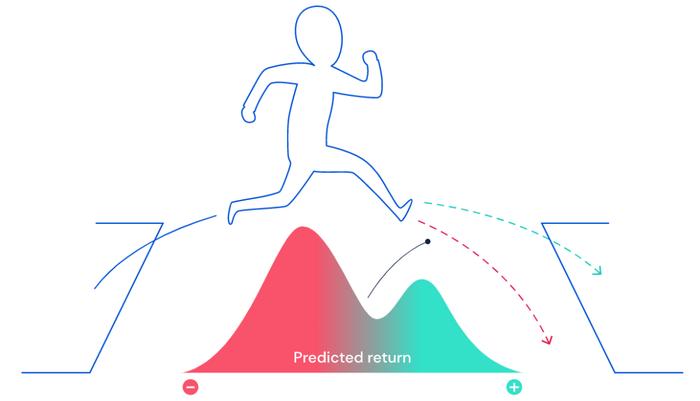
当下一刻出现新信息时,将新的预测与预期的进行比较。如果二者不同,则计算出回报的差异,并使用此“即时差异”将旧预测调整为新预测,使期望预测与现实相匹配,整个预测链逐渐变得更加准确。
大约在同一时期,上世纪80年代末到90年代初,神经科学家也在努力了解多巴胺神经元的行为。这些神经元的放电与奖励机制有关,但其反应也取决于感觉输入,并且会随着经验而改变。
逐渐地,一些研究人员开始将神经科学和AI的最新发现联系起来。研究人员发现,某些多巴胺神经元的反应代表了奖励预测的错误:也就是说,当动物获得的奖励比预期的多或少时,多巴胺神经元就会放电。
这些研究人员据此推测,人的大脑也在使用TD学习算法:计算奖励预测误差,通过多巴胺信号向大脑广播。从那时起,多巴胺的奖励预测误差理论已在数千个实验中得到测试和验证,并且已成为神经科学中最成功的定量理论之一。
破解“快乐之源”多巴胺的分布密码
由于分布式TD算法在人工神经网络中是如此强大,因此自然而然地出现了一个问题:大脑中是否也使用了分布式TD算法?
DeepMind与哈佛大学的实验室合作,分析了小鼠的多巴胺细胞的记录。记录是在小鼠执行完好学习的任务后得到的,在这些任务中它们收到了无法预测的奖励(图4)。评估了多巴胺神经元的活性是否与标准TD或分布TD一致。
第一个问题是,是否可以在神经数据中发现这种奖励预测。
过去,我们已经知道多巴胺细胞会改变其放电速率指示预测错误,也就是说,当收到的奖励与预测奖励完全相同时,预测误差应该为零,因此放电速率没有变化。对于每个多巴胺细胞,我们确定了这个不会改变放电速率的临界奖励。我们称之为“反转点”。
接下来的问题是,不同多巴胺细胞的“反转点”奖励是否不同。下图表明,一些细胞预测出了非常大的奖励,还有的细胞预测很少,其差异程度明显超出了随机差异。
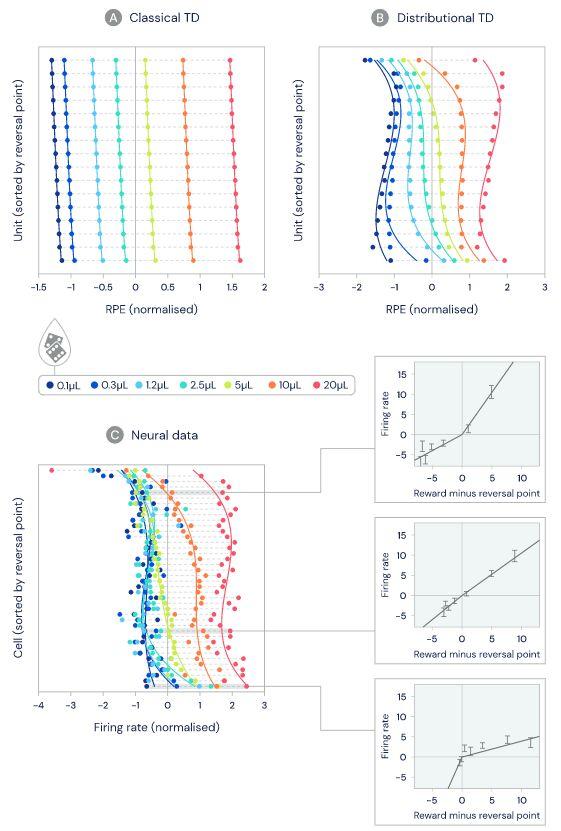
图1:在此任务中,给小鼠喝水的奖励是随机确定的,数量是可变的
奖励预测中的这些差异是由正向或负向奖励预测错误的选择性放大引起的。通过测量不同多巴胺细胞表现出“积极”和“消极”预测的扩大程度的差异,在不同细胞之间发现了明显的差异性,这种差异已经超出了噪声的范围。
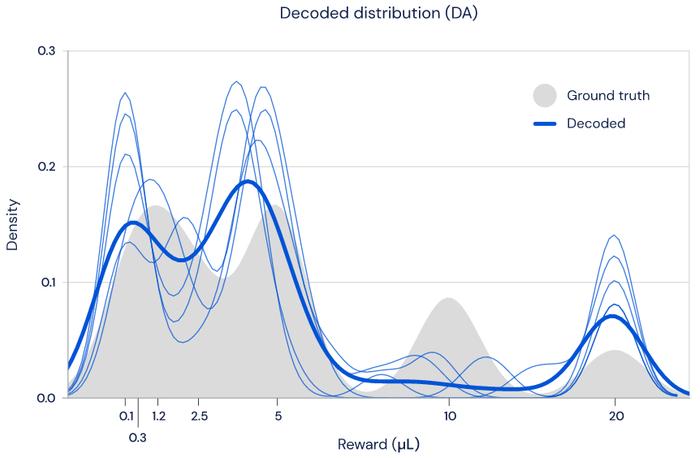
图 2:多巴胺细胞编码学习的奖励分布。可以根据放电率对奖励分布进行解码。灰色阴影区域是任务中奖励的真实分配。每个浅蓝色轨迹显示解码程序的示例。暗蓝色是平均运行时间。
最后一个问题是,是否可以从多巴胺细胞的放电速率中解码奖励分布。如上图所示,我们发现确实有可能仅使用多巴胺细胞的放电速率来重建奖励分布(蓝色),该分布与实际奖励分布(灰色区域)非常接近。
结论:分布式强化学习是一条通向更先进AI的光明大道
这项研究证明,大脑中确实存在与AI模型中类似的分布式强化学习机制,这对人工智能和神经科学都有意义。
首先,它验证了分布强化学习是一条通向更先进AI能力的光明大道。
“如果大脑正在使用它,这应该是一个好主意,”DeepMind神经科学研究主任、该论文的主要作者之一Matthew Botvinick说:“它告诉我们,这是一种可以在现实世界中扩展的计算技术,它将很好的适应其他计算过程。”

Matthew Botvinick
其次,这一发现为神经科学提出了新问题,为理解心理层面的健康和动机提供了新见解。
例如,有“悲伤”和“快乐”的多巴胺神经元意味着什么?如果大脑有选择地只听其中一个或另一个,它会导致化学失衡和诱发抑郁吗?
从根本上说,通过进一步解码大脑的过程,研究结果还揭示了创造人类智力的因素。Botvinick说:“它为我们提供了关于日常生活中大脑活动的新视角。”
最后,研究人员希望这些问题的提出和解答,能推动神经科学领域的技术进步,并将其成果反哺AI研究,实现良性循环。
参考链接:
https://www.newscientist.com/article/2230327-deepmind-found-an-ai-learning-technique-also-works-in-human-brains/
https://www.vox.com/future-perfect/2020/1/15/21067228/ai-brain-protein-folding-google-deepmind
https://www.technologyreview.com/s/615054/deepmind-ai-reiforcement-learning-reveals-dopamine-neurons-in-brain/









